



KI-Wiki
Reiter
Grenzen und Risiken
KI ist weder ein Wundermittel, das alle Probleme der Bildung oder gar der Menscheit zu lösen vermag, noch ist sie der «böse» Supercomputer, der die Weltherrschaft an sich reissen will. Bei der Nutzung von KI muss man – wie bei allen anderen Tools und Medien auch – Chancen wie Risiken gegeneinander abwägen. Es hilft deshalb, auch die Grenzen und Risken von KI zu kennen, um damit verantwortungsvoll umgehen zu können.
Wie jede Technik hat auch KI Grenzen. Die Sozialwissenschaftlerin Kate Crawford hat hierzu provokant formuliert, dass KI weder «künstlich» noch «intelligent» sei. Sie schreibt:
AI is neither artificial nor intelligent. Rather, artificial intelligence is both embodied and material, made from natural resources, fuel, human labor, infrastructures, logistics, histories, and classifications. AI systems are not autonomous, rational, or able to discern anything without extensive, computationally intensive training with large datasets or predefined rules and rewards.[1]
Damit KI ihre teils erstaunlichen Leistungen zeigen kann, braucht es natürliche Ressourcen, Infrastrukturen und vor allem menschliche Vorarbeit. So ist KI auf den Abbau Seltener Erden angewiesen, die in unseren digitalen Endgeräten stecken. Serverfarmen, auf denen die für KI erforderlichen riesigen Datenmengen liegen, benötigen nicht nur Platz, sondern auch grosse Mengen Energie zur Kühlung der Server. Man schätzt, dass etwa vier bis fünf Prozent des globalen Energieverbrauchs auf den Betrieb von Rechenzentren zurückgehen.[2] Und die Datensätze, mit denen die Algorithmen der KI trainiert werden, müssen oftmals vorab klassifiziert werden. Dies erledigen beispielsweise sogenannte Clickworker, die für wenige Cent Bilder und andere Daten klassifizieren müssen – also beispielsweise Bilder als Katze oder Hund kennzeichnen. Diese Klassifikationsarbeit leisten wir aber auch, wenn wir Captchas ausfüllen, um nachzuweisen, dass wir kein Bot sind. Gleichzeitig helfen wir damit einer KI dabei, zu erkennen, wie Ampeln, Motorräder und Busse aussehen – eine Fähigkeit, die beispielsweise beim autonomen Fahren wichtig ist.

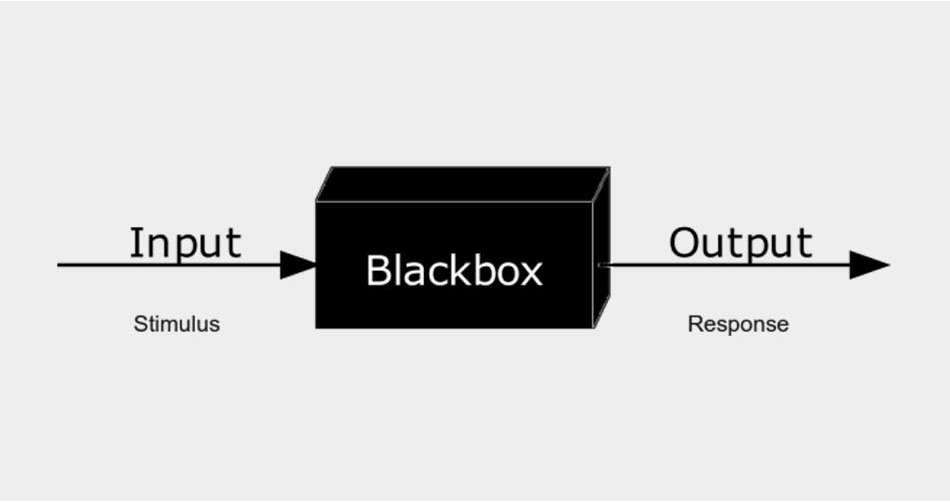
Blackbox KI
Da die der KI zugrunde liegenden Kriterien im Deep Learning in unzähligen verborgenen Schichten stecken, ist es selbst für Programmierer:innen fast unmöglich, die Funktionsweise einer konkreten KI zu identifizieren. Wie der Algorithmus zu seinem Ergebnis kommt, bleibt daher oft unklar. Als man beispielsweise eine KI darauf trainiert hat, Bilder von Wölfen und Huskys zu unterscheiden, hat dies mit dem Trainingsdatensatz treffsicher funktioniert. Bei anderen Bildern lag die KI hingegen oft daneben. Schnell wurde klar, dass dies vor allem Bilder betraf, bei denen Huskys im Schnee beziehungsweise Wölfe vor grünem Hintergrund zu sehen waren. Im Trainingsdatensatz waren Wölfe stets im Schnee und Huskys vor Häusern oder auf Rasenflächen abgebildet. Die KI hat also nicht – wie erhofft – gelernt, die spezifischen Merkmale von Huskys und Wölfen zu unterscheiden, sondern lediglich weissen und grünen Hintergund kategorisiert.

Letztlich hat man hier und in anderen Fällen jeweils nur Einsicht in das, was man hineingibt (Input), und in das, was man als Ergebnis (Output) erhält. Davon ausgehend, muss man einschätzen, ob die KI gute Ergebnisse liefert und wie sie zu diesen kommt. Die genauen Mechanismen im Innern bleiben unzugänglich. Dies ist als Blackbox-Problem bekannt. Dies kann zum sogenannten Algorithmic Bias führen.
Zuletzt geändert: 1. Nov 2024, 11:53, Röhl, Tobias [tobias.roehl@phzh.ch]