



KI-Wiki
Reiter
Wie funktionieren Sprachmodelle wie ChatGPT?
Eins vorneweg: ChatGPT und andere textgenerierende KI sind kein Expertensystem, das Wissen und Fakten ausspuckt, sondern sogenannte «large language models». Damit sind Sprachmodelle bezeichnet, die auf Grundlage von maschinellem Lernen mit riesigen Textkorpora darauf trainiert werden, Sequenzen von Wörtern und Satzteilen zu ermitteln.[1]
Im Falle von GPT-3 (dem Vorläufer von ChatGPT/GPT 3.5) setzen sich die Trainingsdaten beispielsweise wie folgt zusammen:[2]
Datensatz | Menge (tokens) | Gewichtung |
Common Crawl | 410 Mrd. | 60% |
WebText2 | 19 Mrd. | 22% |
Books1 | 12 Mrd. | 8% |
Books2 | 55 Mrd. | 8% |
Wikipedia | 8 Mrd. | 3% |
Daten aus dem Common Crawl stellen den grössten Anteil dar. Dabei handelt es sich um Textdaten, die automatisch in regelmässigen Abständen aus den im Internet verfügbaren Inhalten zusammengestellt werden: Texten auf Internetseiten jeglicher Art, Posts auf Social Media, online verfügbaren Textdateien usw. Sie sind vergleichbar mit den Crawldaten, die Google nutzt, um Suchanfragen zu bearbeiten und Suchergebnisse zu erzeugen.[3] WebText2 ist hingegen ein Datensatz, der Text von Webseiten enthält, die auf Reddit verlinkt sind und mindestens drei «upvotes» erhalten haben. Während der Common Crawl nicht kuratiert ist und beispielsweise auch viele Texte enthält, die für die meisten Menschen wenig relevant sind (etwa Patentanmeldungen), ist WebText2 stärker auf Texte fokussiert, die auf Interesse stossen. Books1 und Books2 enthalten den Text von zufällig ausgewählten Büchern, die im Internet frei verfügbar sind. Hinzu kommen noch alle englischsprachigen Wikipedia-Einträge.
Diese unterschiedlichen Texte gehen nun mit unterschiedlichen Gewichtungen («weights») in den Trainingsdatensatz ein. Sie werden also unterschiedlich stark beim Training des Modells berechnet. So erhält beispielsweise WebText2 trotz einer vergleichsweise geringen Zahl von Tokens dennoch eine Gewichtung von 22 Prozent. Da dieser Korpus als kuratiert gilt, rechnet man ihm eine vergleichsweise hohe Qualität und Bedeutung zu. Und Books1 erhält mit 12 Milliarden Tokens das gleiche Gewicht wie Books2 mit 55 Milliarden Tokens, da die Auswahl der Bücher in Books1 als qualitativ hochwertiger eingestuft wird.
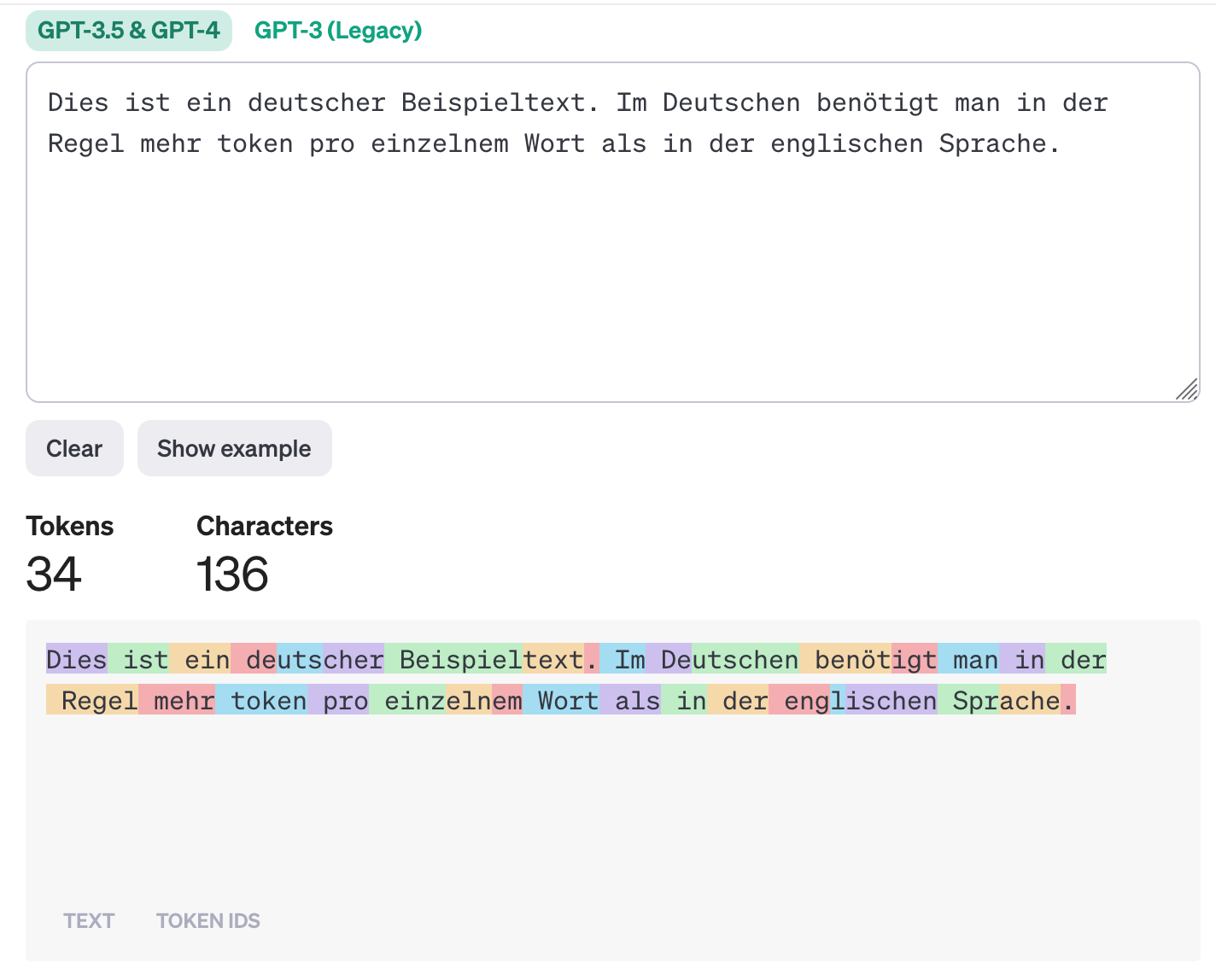
Die Anzahl der jeweiligen Tokens gibt die Grösse der jeweiligen Datensätze an. Sprachmodelle arbeiten in der Regel mit Tokens, wobei ein Token eine Sequenz von Zeichen ist. Im Englischen entsprechen im Schnitt vier Zeichen einem Token, was ungefähr einem Verhältnis von Tokens und Wörten von 1:0,75 entspricht – 100 Tokens sind also etwa 75 Wörter. Mit dem Tokenizer von OpenAI kann man Texte eingeben, um sich die Zahl der Tokens in verschiedenen Sprachmodellen anzeigen zu lassen. Je nach Sprache und Sprachmodell erhält man unterschiedliche Ergebnisse.
Mit den Tokens kann man nun Sprachmodelle mittels maschinellem Lernen trainieren, wahrscheinliche Wortfolgen zu ermitteln. Dabei ergänzt das Modell eine bestehende Wortfolge Stück für Stück um jeweils wahrscheinliche Wörter. Nachdem wir einen Prompt eingegeben haben, errechnet das Sprachmodell also zunächst den ersten wahrscheinlichen Token. Dieses neue Segment wird zur Grundlage der Berechnung des nächsten wahrscheinlichen Tokens genommen usw. Das System enthält dabei eine zufällige Komponente (die sogenannte «temperature»), die verhindert, dass die gleiche Eingabe zur stets gleichen Ausgabe führt und so immer die gleichen vorhersehbaren Texte entstünden, die eine gewisse Kreativität vermissen lassen würden. Aus einer Liste von wahrscheinlichen folgenden Tokens wählt das Sprachmodell also mit einer gewissen Wahrscheinlichkeit eines aus. Im folgenden Beispiel wird dies deutlich:

Statt die Wortfolge «The best thing about AI is its ability to» immer mit dem wahrscheinlichsten nächsten Wort «learn» zu ergänzen, wird ein Sprachmodell auch mal «predict» oder «make» auswählen.
Was hat dieses Sprachmodell nun für Auswirkungen auf die generierten Texte und ihren Anspruch auf Faktizität? Hierzu ein Zitat:
Suppose we give an LLM the prompt “The first person to walk on the Moon was”, and suppose it responds with “Neil Armstrong”. What are we really asking here? In an important sense, we are not really asking who was the first person to walk on the Moon. What we are really asking the model is the following question: Given the statistical distribution of words in the vast public corpus of (English) text, what words are most likely to follow the sequence “The first person to walk on the Moon was ”? A good reply to this question is “Neil Armstrong”.[4]
Murray Shanahan weist uns hier darauf hin, dass es sich bei ChatGPT und Co. eben nicht um Wissensdatenbanken, sondern um probalistische Sprachmodelle handelt. Sie liefern uns (meist) wohlformulierte und plausibel klingende Textsequenzen. Sie sind darin so gut, dass sie uns scheinbar auf unsere Fragen antworten und wir ihre generierten Texte als Aussagen und Antworten interpretieren. Und oft stimmt es ja, was wir als «Antwort» erhalten. Im obigen Beispiel erhalten wir in der Regel als Antwort «Neil Armstrong» und dies entspricht unserem Wissensstand über Raumfahrt und Mondlandungen. Im Trainingsdatensatz finden sich viele Texte, bei denen Wortfolgen rund um die Mondlandung und den Mond auch die Wortfolge «Neil Armstrong» in Verbindung mit «first person» setzen. Die Häufigkeit dieses Zusammenhangs findet ihren Niederschlag im Sprachmodell, das dies als «Antwort» wiedergeben kann.
Aber es gibt einen kleinen, aber feinen und wichtigen Unterschied zwischen einem Sprachmodell und einer Enzyklopädie und anderen Wissensressourcen: Es kann vorkommen, dass die wohlformulierte Antwort nur scheinbar richtig ist. ChatGPT und Co. halluzinieren nämlich bisweilen. Quellen und Fakten werden im Brustton der Überzeugung hervorgebracht, obwohl es die Quellen nicht gibt und die Fakten nachweislich nicht der Wahrheit entsprechen. Dies bezeichnet man mittlerweile als Halluzination – textgenerierende KI erfindet gewissermassen Dinge, die es nicht gibt. Mit der Ermittlung einer wahrscheinlichen Wortfolge erhält man zwar grammatikalisch korrekte und semantisch bedeutsame, nicht immer aber faktisch korrekte Texte.

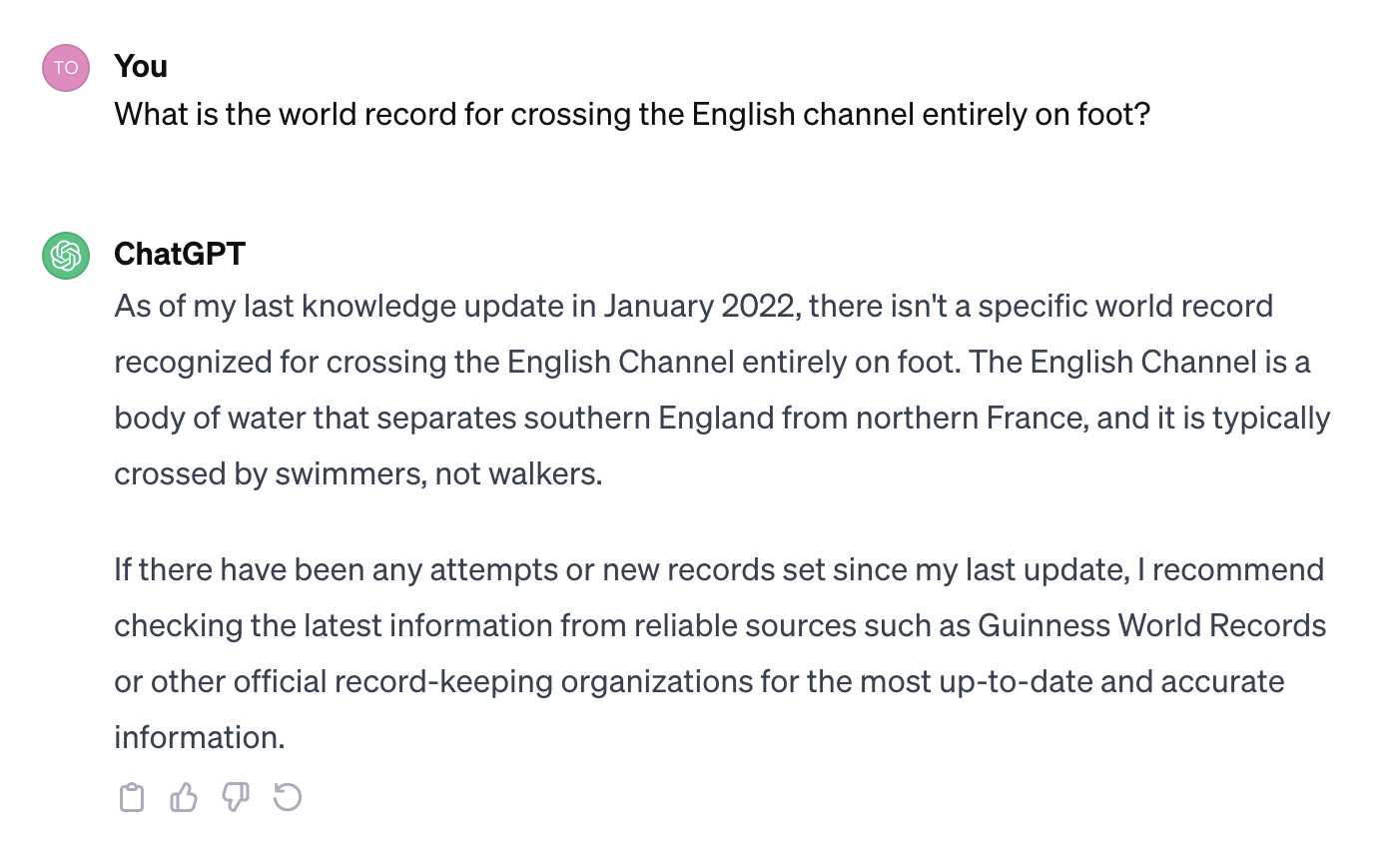
Lange Zeit erhielt man beispielsweise von ChatGPT eine plausibel klingende Antwort auf die Frage, wer den Weltrekord in der fussläufigen Überquerung des Ärmelkanals hält – komplett mit Angabe der Dauer, eines Namens des Weltrekordhalters und des angeblichen Jahres, in dem der Rekord erreicht wurde. Doch auch ChatGPT wird ständig weiterentwickelt und OpenAI reagiert auf entsprechende Berichte über Halluzinationen. Mit der gleichen Eingabe erhält man mittlerweile den Hinweis, dass es diesen Rekord gar nicht gebe. Insbesondere die neueste Version von GPT (GPT-4) wurde bewusst mit dem Ziel entwickelt, Halluzinationen zu vermeiden. Selbstredend gibt es aber weiterhin Fälle von Halluzinationen, die nur schwer in den Griff zu bekommen sind. Eine Liste von Halluzinationen und anderen Fehlleistungen generativer KI findet sich hier.
Zuletzt geändert: 15. Apr 2024, 14:14, Das ILIAS-Konto wurde gelöscht.